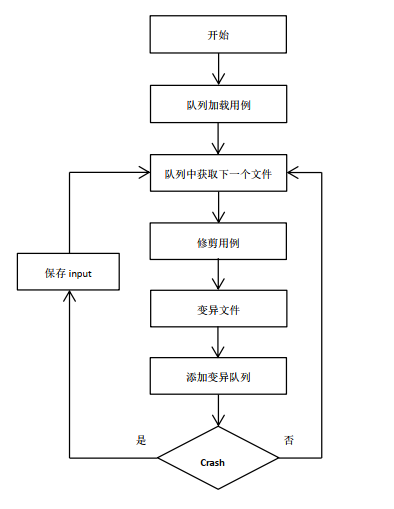
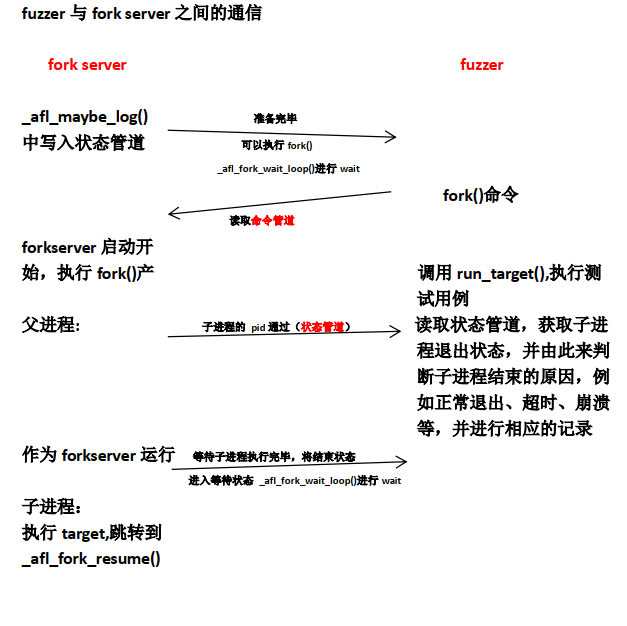
Simplifying a bit, the overall algorithm can be summed up as: 1) Load user-supplied initial test cases into the queue, 2) Take next input file from the queue, 3) Attempt to trim the test case to the smallest size that doesn't alter the measured behavior of the program, 4) Repeatedly mutate the file using a balanced and well-researched variety of traditional fuzzing strategies, 5) If any of the generated mutations resulted in a new state transition recorded by the instrumentation, add mutated output as a new entry in the queue. 6) Go to 2.
interest变异: interest 8/8,每次对8个bit进替换,按照每8个bit的步长从头开始,即对文件的每个byte进行替换 interest 16/8,每次对16个bit进替换,按照每8个bit的步长从头开始,即对文件的每个word进行替换 interest 32/8,每次对32个bit进替换,按照每8个bit的步长从头开始,即对文件的每个dword进行替换 其中interest value的值在config.h已经设定好 #define INTERESTING_8 \ -128, /* Overflow signed 8-bit when decremented */ \ -1, /* */ \ 0, /* */ \ 1, /* */ \ 16, /* One-off with common buffer size */ \ 32, /* One-off with common buffer size */ \ 64, /* One-off with common buffer size */ \ 100, /* One-off with common buffer size */ \ 127 /* Overflow signed 8-bit when incremented */ 可以看到,用于替换的基本都是可能会造成溢出的数;与之前相同,effector map仍然会用于判断是否需要变异;
dictionary变异: user extras (over),从头开始,将用户提供的tokens依次替换到原文件中 user extras (insert),从头开始,将用户提供的tokens依次插入到原文件中 auto extras (over),从头开始,将自动检测的tokens依次替换到原文件中 tokens:在进行bitflip 1/1变异时,对于每个byte的最低位(least significant bit)翻转还进行了额外的处理:如果连续多个bytes的最低位被翻转后,程序的执行路径都未变化,而且与原始执行路径不一致,那么就把这一段连续的bytes判断是一条token。
havoc变异: 随机选取某个bit进行翻转 随机选取某个byte,将其设置为随机的interesting value 随机选取某个word,并随机选取大、小端序,将其设置为随机的interesting value 随机选取某个dword,并随机选取大、小端序,将其设置为随机的interesting value 随机选取某个byte,对其减去一个随机数 随机选取某个byte,对其加上一个随机数 随机选取某个word,并随机选取大、小端序,对其减去一个随机数 随机选取某个word,并随机选取大、小端序,对其加上一个随机数 随机选取某个dword,并随机选取大、小端序,对其减去一个随机数 随机选取某个dword,并随机选取大、小端序,对其加上一个随机数 随机选取某个byte,将其设置为随机数 随机删除一段bytes 随机选取一个位置,插入一段随机长度的内容,其中75%的概率是插入原文中随机位置的内容,25%的概率是插入一段随机选取的数 随机选取一个位置,替换为一段随机长度的内容,其中75%的概率是替换成原文中随机位置的内容,25%的概率是替换成一段随机选取的数 随机选取一个位置,用随机选取的token(用户提供的或自动生成的)替换 随机选取一个位置,用随机选取的token(用户提供的或自动生成的)插入
git clone https://github.com/dyninst/dyninst.git cd dyninst mkdir build cd build cmake -DBOOST_LIBRARYDIR=/usr/lib/x86_64-linux-gnu make sudo make install
Usage: ./afl-dyninst -i <binary> -o <binary> -l <library> -e <address> -s <number> -i: Input binary -o: Output binary -l: Library to instrument (repeat for more than one) -e: Entry point address to patch (required for stripped binaries) -r: Runtime library to instrument (path to, repeat for more than one) -s: Number of basic blocks to skip -v: Verbose output example: afl-dyninst -i testbin -o testbin_ins to fuzz: export AFL_SKIP_BIN_CHECK=1 afl-fuzz -i in -o out testbin_ins