在上一篇博客中对栈溢出的相关原理进行了浅析,接下来我找了个实例来进一步来加强理解,首先我们来看代码
1 | //vuln.c |
操作系统提供了许多安全机制来试图降低或阻止缓冲区溢出攻击带来的安全风险,包括DEP、ASLR等。在编写漏洞利用代码的时候,需要特别注意目标进程是否开启了DEP(Linux下对应NX)、ASLR(Linux下对应PIE)等机制,例如存在DEP(NX)的话就不能直接执行栈上的数据,存在ASLR的话各个系统调用的地址就是随机化的。所以在编译之前,首先要来关闭掉linux系统栈保护机制。
学习下相关的保护机制,checksec工具可以来检查各个保护机制是否打开

依次来看看上图中的各个保护机制,这个具体可参考(上善若水的博客),下面应用一部分当学习笔记记录吧:
CANNARY(栈保护):上图中表示栈保护功能开启,栈溢出保护是一种缓冲区溢出攻击缓解手段,当函数存在缓冲区溢出攻击漏洞时,攻击者可以覆盖栈上的返回地址来让自己已经设计好的shellcode得到执行。而当启用栈保护后,函数开始执行的时候会先往栈里插入cookie信息,当函数真正返回的时候会验证cookie信息是否合法,如果不合法就停止程序运行。攻击者在覆盖返回地址的时候往往也会将cookie信息给覆盖掉,导致栈保护检查失败而阻止shellcode的执行。在Linux中我们将cookie信息称为CANARY。FORTIFY:FORTIFY其实非常轻微的检查,用于检查是否存在缓冲区溢出的错误。适用情形是程序采用大量的字符串或者内存操作函数,如memcpy,memset,stpcpy,strcpy,strncpy,strcat,strncat,sprintf,snprintf,vsprintf,vsnprintf,gets以及宽字符的变体。NX(DEP):NX(No-eXecute)即为不可执行的意思,基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。工作原理如图:
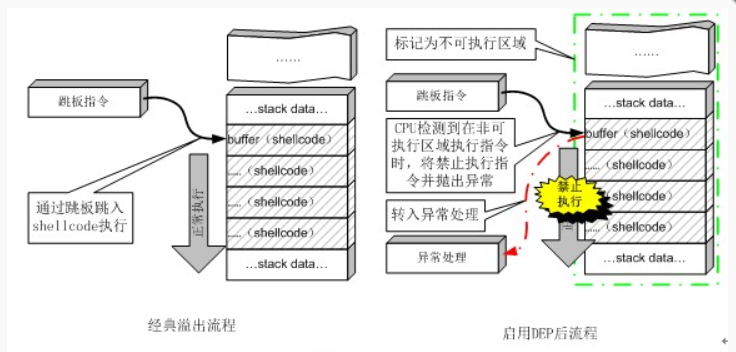
PIE(ASLR):一般情况下NX(Windows平台上称其为DEP)和地址空间分布随机化(ASLR)会同时工作。内存地址随机化机制(address space layout randomization),有以下三种情况1
2
30 - 表示关闭进程地址空间随机化。
1 - 表示将mmap的基址,stack和vdso页面随机化。
2 - 表示在1的基础上增加栈(heap)的随机化。可以防范基于
Ret2libc方式的针对DEP的攻击。ASLR和DEP配合使用,能有效阻止攻击者在堆栈上运行恶意代码。RELRO:在Linux系统安全领域数据可以写的存储区就会是攻击的目标,尤其是存储函数指针的区域。 所以在安全防护的角度来说尽量减少可写的存储区域对安全会有极大的好处.GCC, GNU linker以及Glibc-dynamic linker一起配合实现了一种叫做relro的技术:read only relocation。大概实现就是由linker指定binary的一块经过dynamic linker处理过relocation之后的区域为只读.设置符号重定向表格为只读或在程序启动时就解析并绑定所有动态符号,从而减少对
GOT(Global Offset Table)攻击。RELRO为”Partial RELRO”,说明我们对GOT表具有写权限。
在利用程序在编译之前我们首先要关闭系统的ASLR 方法,checksec如下 所以:

接下来,我们要如何利用该程序的漏洞呢,所以要做的是覆盖返回地址,即覆盖掉栈中的返回地址,从而让指令寄存器去执行我之前设定好的shellcode,在之前,我们先看下该段代码的反汇编代码
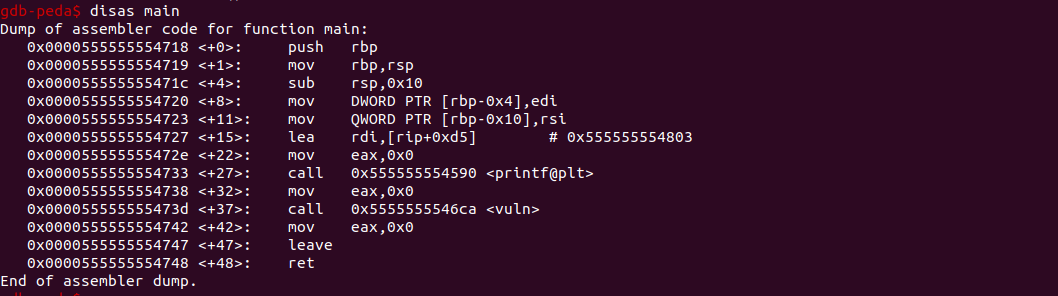
该段程序当read()将400字节复制到一个80字节的buffer时,显然存在缓冲区溢出,下面我们构造我们的exp,来看看是否能够覆盖RIP
1 | #!/usr/bin/env python |
我们将利用这个exp来创建一个含有400个”A” 字符的”in.txt“文件,并且将典例加载进gdb并将in.txt的内容重定向到典例中
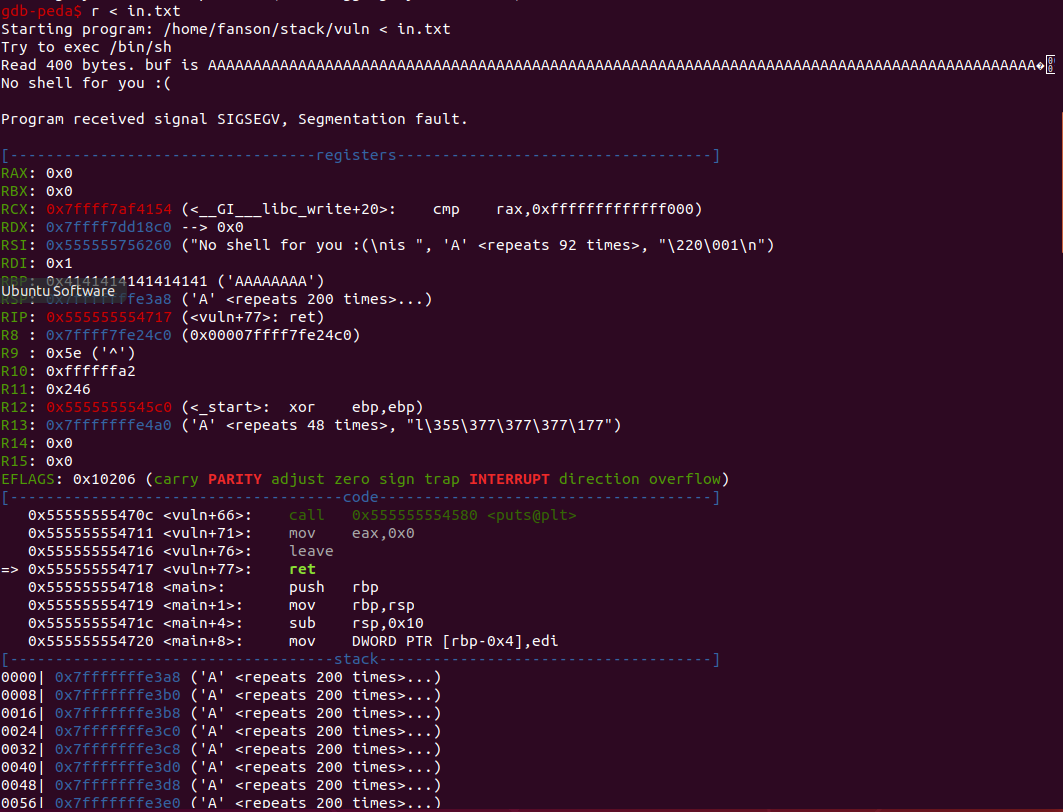
程序显然崩掉了,但是却没有覆盖到RIP,因为我们已覆盖的RIP带有一个无效地址,事实上我们没控制到RIP,为了控制RIP,我们需要用0x0000414141414141覆盖(代替)它,因此真正的目标是找到覆盖了RIP的偏移(带有一个非标准地址)。我们可以使用一种cyclic模板找到这个偏移,并且再次运行检查RSP的内容,最后便可以看到偏移
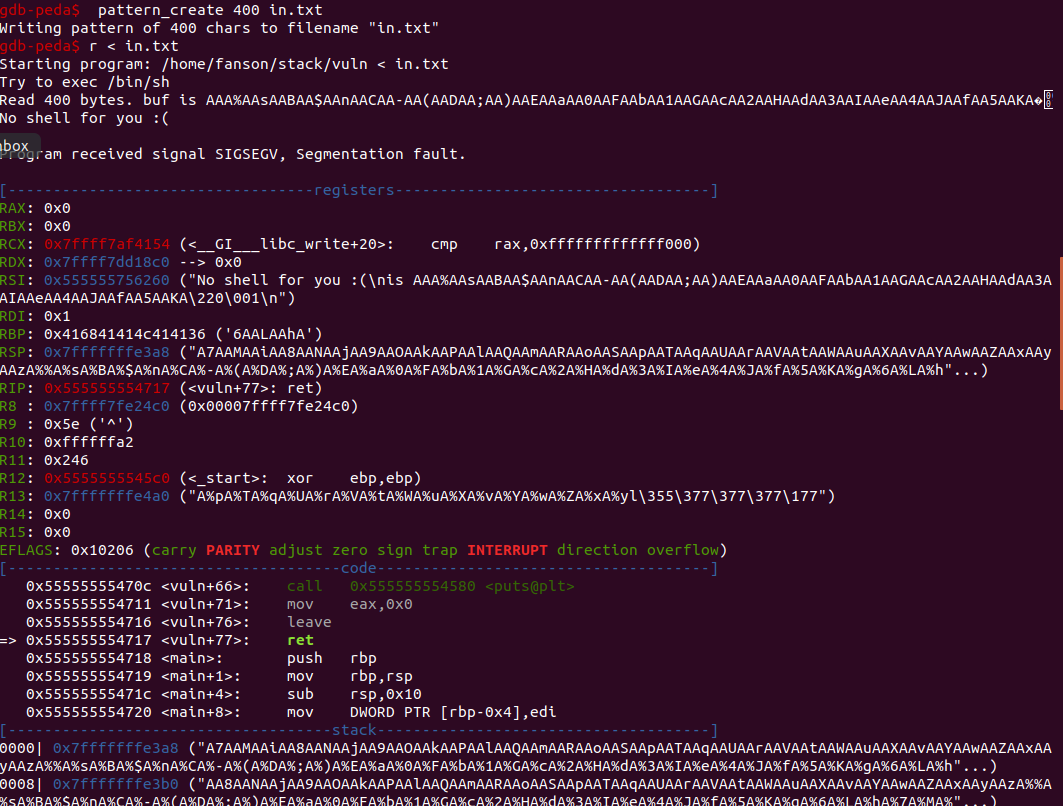
因此,RIP在偏移104上.让我们重新构造我们的exp并看看我们这次是否可以覆盖RIP:
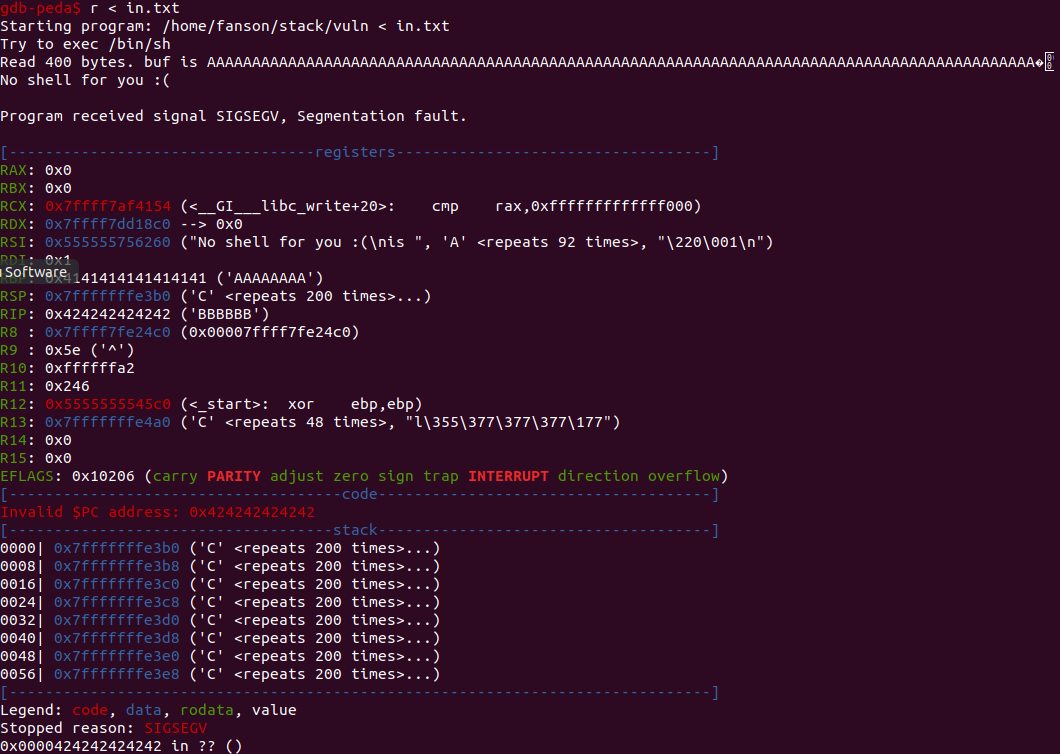
很棒,我们已经彻底控制了RIP。最后,我们可以继续构造我们的shellcode。